
Veriler her yerde ve şimdi her zamankinden daha fazlalar, onları keşfetmek için parmaklarımızın ucunda ücretsiz araçlar var. Verilerle uğraşmak ve onların keşfi için en popüler python kitaplıklarından biri Pandas’tır. Ancak dürüst olmak gerekirse en sezgisel sözdizimine sahip değil. Bu sadece öğrenmeyi oldukça zorlaştırmakla kalmaz, aynı zamanda her gün Pandas’la çalışmazsanız sözdizimini kafanızda tutmak oldukça zor olur.
Ayrıca Pandas kodu yazmak bazen kuzeyli bir savaş baltasıyla sebze doğramaya benzeyebiliyor: İşi yapıyor ve bir şekilde bunu yaparken kendinizi iyi hissedebilirsiniz, ancak sonuca baktığınızda, hiç iyi görünmeyebilir, bu yüzden bu karmaşaya aktif olarak katılmamayı tercih edebilirsiniz.
bamboolib İle Tanışın
bamboolib, verilerinizi hazırlamanıza ve keşfetmenize izin veren ücretsiz bir GUI’dir. Verilerinizi her düzenlediğinizde ve araçla oluşturduğunuz her etkileşimli çizim için, sizin için python kodunu oluşturacaktır. Bu sayede adımlarınızı takip edebilir, analizlerinizi tekrarlayabilir ve interaktif raporlar oluşturabilirsiniz.
Kodlama yerine iç görüler edinmeye ve paylaşmaya odaklanın
Bir Jupyter Notebook/JupyterLab kullanarak Python Pandas ile verileri analiz etmek ve keşfetmek istiyorsanız, ancak
a) tamamen acemiyseniz
b) her zaman panda sözdizimine bakmak istemiyorsanız bu blog yazısı tam size göre. Sadece Notebook’unuza çok fazla kod girmeden verilerinizi hızlı bir şekilde anlamak istiyorsunuz.
Bu çalışma için Global deforestation — Soybean production and use adlı veri setini kullanacağız. Github sayfasından ilgili sete ulaşabilirsiniz. Kısacası, veri seti hayvan yemi, insan gıdası ve yakıt için kaç ton soya fasulyesi üretildiğini gösteriyor.
bamboolib’i Yüklemek
Başlamadan önce, bamboolib’i dokümanlarda anlatıldığı gibi kuralım.
pip install bamboolib
python -m bamboolib install_extensions
Küresel soya fasulyesi kullanımını keşfetmek
Hangisini tercih ederseniz, bir Jupyter Notebook veya JupyterLab açalım. Verileri yazarak kendiniz alabilirsiniz.
import pandas as pd
soybean_use = pd.read_csv(‘https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2021/2021-04-06/soybean_use.csv’)
Bamboolib kullanarak bir göz atalım. Not defteri hücrenizde aşağıdaki kodu çalıştırın.
import bamboolib as bam soybean_use
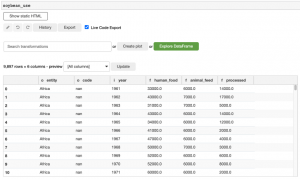
İçinde hangi değerlerin beklendiğinden emin olmadığınız için sütun varlığı dikkatinizi çekebilir. İlk gözlemler Afrika’dan, bu yüzden varlığın kıtaları içerebileceğini düşünebilirsiniz, ancak verileri kaydırmak, varlığın ülkeleri ve “Net Gıda İthalat Yapan Gelişmekte Olan Ülkeler” gibi bazı yapay kümeleri de içerdiğini ortaya koyuyor.
Sadece ülkelerle ilgileniyoruz. Peki geri kalanı nasıl kaldırılır?
Kodun Ülke Koduna atıfta bulunduğuna dair bir his var (şaka yapıyoruz, aslında veri açıklamasında öyle yazıyor) bu yüzden kodu olmayan tüm satırları bırakırsak, verilerimizde yalnızca ülkeler olmalı.
Ancak herhangi bir satırı körü körüne atmadan önce, ilk olarak eksik kodları olan varlıkların gerçekten de ülkelerden başka bir şey olup olmadığını kontrol ediyoruz (“çünkü biz dikkatli veri bilimcileriyiz!”).
Bunu, kodun eksik olduğu tüm satırları filtreleyerek ve ardından verilerde artık ülke olmadığını doğrulamak için filtrelenmiş verilere bakarak yapıyoruz.
Bunun için arama alanında “filtre” aratıyoruz ve kodun eksik olduğu tüm satırları filtrelemek için kullanıcı ara yüzünü kullanıyoruz.
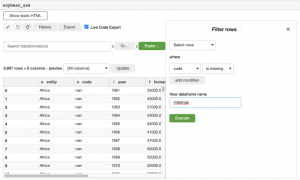
Orijinal veri kümesinin üzerine yazmak istemediğimiz için bu geçici verilere yeni adın eksik olduğunu verdik. Filtreyi çalıştırdıktan sonra, ara yüzden 8.163 satırın (verilerin %82’si) kaldırıldığına dair bazı geri bildirimler alıyoruz. Ayrıca, bamboolib bizim için aşağıdaki kodu üretti:
missings = soybean_use.loc[soybean_use[‘code’].isna()]
Yeni eksik veri çerçevesinin varlık sütun başlığına tıkladığımda bir sütun özeti alıyoruz.
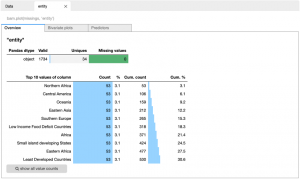
Tüm değer sayımlarını göster düğmesini tıkladık ve tüm varlık değerleri arasında gezindik ve beklendiği gibi – verilerde artık ülke yok.
Artık kodun eksik olduğu satırları bırakmanın herhangi bir ülkeyi atmayacağını bildiğimiz için, bu filtreyi yukarıdan (geri al düğmesine tıklayarak) geri alıyoruz ve kodun eksik olmadığı tüm satırları seçiyoruz.
Filtreden sonra verilerimiz şöyle görünüyor.
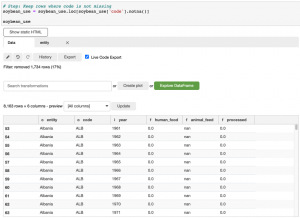
Şimdi kalan sütunlara bir göz atalım.
- yıl belli
- human_food, insan gıdası (tempeh, tofu, soya sütü, edamame fasulyesi vb.) için kullanılan soya miktarını (ton olarak) içerir
- animal_feed, doğrudan hayvanlara verilen soya miktarını (ton olarak) içerir
- işlenmiş, bitkisel yağ, biyoyakıt ve soya küspesi gibi işlenmiş hayvan yemi olarak işlenen soya (ton olarak) miktarını içerir.
Küçük Bir Veri Tartışması
Şu anda veriler geniş formatta, ancak daha kolay çizim için uzun formatta olmasını istiyoruz (Uzun formatlı verilere sahip olmak – düzenli veri olarak da bilinir – toplamaları ve çizimi daha kolay hale getirir. Neden diye sorabilirsiniz. Birazdan göreceksiniz).
Bunun için verilerimizi yeniden şekillendirmemiz gerekiyor.
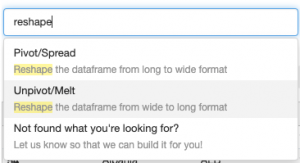
Kullanıcı ara yüzünde “yeniden şekillendir” ifadesini aratıyoruz ve aralarından seçim yapabileceğimiz iki seçenek görüyoruz. Geniş → uzun gitmek istediğimiz için “Unpivot/Melt” dönüşümünü seçiyoruz.
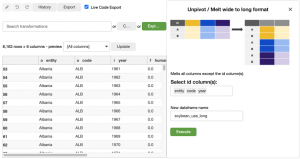
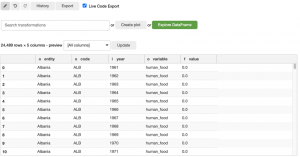
Oluşturulan kod:
# Step: Melt columns based on the index columns entity, code, year
soybean_use_long = soybean_use.melt(id_vars=[‘entity’, ‘code’, ‘year’])
Ayrıca iki sütuna değişken vereceğiz ve daha sezgisel adlara değer vereceğiz. Bunun için “sütunları yeniden adlandır” dönüşümünü kullanıyoruz.
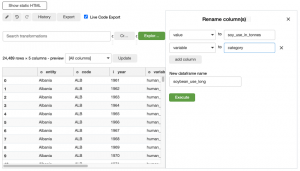
Oluşturulan kod:
# Step: Rename multiple columns
soybean_use_long = soybean_use_long.rename(columns={‘value’: ‘soy_use_in_tonnes’, ‘variable’: ‘category’})
Bamboolib’in gelecek projelerinizde verilerinizden daha hızlı ve daha az bilişsel yük ile iç görüler elde etmenize yardımcı olacağını umuyoruz.