
Veri Setine Genel Bakış
Bu veri seti, gerçek ve sahte banknotları ayırt etmekle ilgilidir. Veriler, gerçek ve sahte banknot benzeri örneklerden alınan görüntülerden elde edildi. Dijitalleştirme için genellikle baskı denetimi için kullanılan endüstriyel bir kamera kullanıldı. Son görüntüler 400×400 piksele sahiptir. Objektifin merceği ve incelenen objeye olan uzaklığı nedeniyle yaklaşık 660 dpi çözünürlüğe sahip gri tonlamalı resimler elde edildi.
ML dünyasına yeni başlayanlar için bu projeyi olabildiğince basit hale getirmeye çalışmaya ve sadece K-Means modelini çalıştırıp sonucu hesaplamaya odaklandık. Bu nedenle, K-Means’in kendisine odaklanmak amacıyla modelleri oluşturmak için sadece iki değişken seçildi, bunlar: V1 (Dalgacık Dönüşümlü görüntünün varyansı) ve V2 (Dalgacık Dönüşümlü görüntünün çarpıklığı).
Adım 1: Verileri Toplayın ve Değerlendirin
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
df = pd.read_csv(‘data_with_labels.csv’)
plt.figure(figsize = [7, 7])
plt.scatter(df.V1, df.V2);
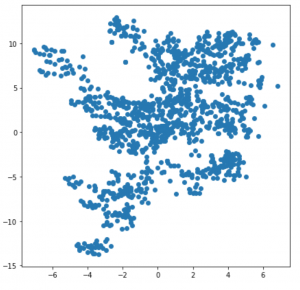
K-Means oluşturmanın ilk adımı, bu veri setinin K-Means için uygun olup olmadığını değerlendirmektir; eğer değilse, o zaman diğer kümeleme modellerini seçmeliyiz. Grafikteki veri dağılımının ne çok geniş ne de tek bir yerde çok merkezli olduğu görülmektedir bu nedenle bu veri kümesinde K-Means ile çalışılabilir. Ancak küresel şekillerde belirgin bir küme yoktur, bu nedenle K-Means modelinin burada mükemmel bir şekilde çalışmasını beklememeliyiz.
Adım 2: K-Means’i Çalıştırın
from sklearn.datasets.samples_generator import (make_blobs, make_circles, make_moons)
from sklearn.cluster import KMeans, SpectralClustering
data = np.column_stack(( df.V1, df.V2))
km_res = KMeans(n_clusters = 2).fit(data)
clusters = km_res.cluster_centers_
df[‘KMeans’] = km_res.labels_
g = sb.FacetGrid(data = df, hue = ‘KMeans’, size = 5)
g.map(plt.scatter, ‘V1’, ‘V2’)
g.add_legend();
plt.scatter(clusters[:,0], clusters[:,1], s=500, marker=‘*’, c=‘r’)
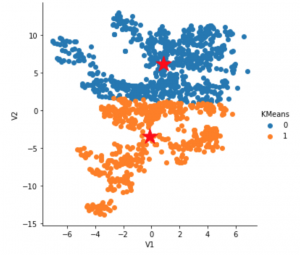
Başlangıç işaretleri, her kümenin merkezidir.
Adım 3: Benzer Sonuçlar Alıp Almadığınızı Görmek İçin K-means’i Birkaç Kez Yeniden Çalıştırın
from sklearn.datasets.samples_generator import (make_blobs, make_circles, make_moons)
from sklearn.cluster import KMeans, SpectralClustering
n_iter = 9
fig, ax = plt.subplots(3, 3, figsize=(16, 16))
ax = np.ravel(ax)
centers = []
for i in range(n_iter):
km = KMeans(n_clusters=2, max_iter=3)
km.fit(data)
centroids = km.cluster_centers_
centers.append(centroids)
ax[i].scatter(data[km.labels_ == 0, 0], data[km.labels_ == 0, 1], label=‘cluster 1’)
ax[i].scatter(data[km.labels_ == 1, 0], data[km.labels_ == 1, 1], label=‘cluster 2’)
ax[i].scatter(centroids[:, 0], centroids[:, 1], c=‘r’, marker=‘*’, s=300, label=‘centroid’)
ax[i].legend(loc=‘lower right’)
ax[i].set_aspect(‘equal’)
plt.tight_layout();
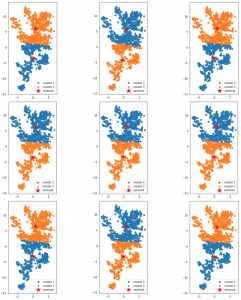
4. Adım: K-Means Hesaplama Sonuçlarını Analiz Edin
df.groupby(‘KMeans’).describe()
![]()
Adım 5: Sonucun Doğruluğunu Hesaplayın
g = sb.FacetGrid(data = df_labels, hue = ‘Class’, size = 5)
g.map(plt.scatter, ‘V1’, ‘V2’)
g.add_legend()
plt.title(“Data With Correct Lables”)
g = sb.FacetGrid(data = df, hue = ‘KMeans’, size = 5)
g.map(plt.scatter, ‘V1’, ‘V2’)
g.add_legend()
plt.title(“K-Means Result”);
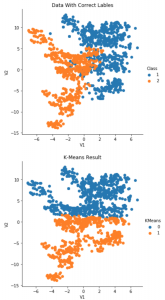
K-Means’in V2 = 1’de yatay bir çizgi ile bölünme eğiliminde olduğunu görebiliriz, buna karşılık Means’in bir dezavantajını gösterdi, o da K-Ortalamaların daha büyük kümelere daha fazla ağırlık vermesiydi.
df[“KMeans”] = df[“KMeans”].map({0: 1, 1: 2})
correct = 0
for i in range(0,1372):
if df.Class[i] == df[“KMeans”][i]:
correct+=1
print(correct/1371)
K-Means Sonucu: Bu K-Means Modelinin doğruluğu %65,3’tür.
Burada herhangi bir veri temizleme ve ön analiz yapmadığımız için %65,3 doğruluk elde etmek oldukça mantıklı. Bununla birlikte, doğruluk oranını optimize etmekle ilgileniyorsanız modellere yerleştirilecek en etkili değişkenleri bulmak için faktör analizi yapmayı düşünebilirsiniz.