
Satranç yapay zekanın başarılarının ilk sıralarında yer alan bir masa oyunu. Oyuncularının bildiği gibi satranç kendi içerisinde birçok olası hamle bulunduruyor. Fakat bu hamleler belirli kurallara göre yapılıyor. Bu kurallar sayesinde algoritmalar yazılıyor ve satranç, bir bilgisayarın tahtadaki taşların durumunu analiz ederek oyuna dahil olabileceği bir hal alıyor. Fakat her oyun satranç gibi belirli kurallar çerçevesinde ilerlemiyor. Pac-Man’i ele alabiliriz. Bu oyunda da tabii ki kurallar var ama göz önünde bulundurulması gereken birçok farklı unsur var. Mesela labirentin şekli, hayaletlerin konumları, temizlenmesi gereken yerler gibi. Bu gibi oyunlar için de şimdiye kadar yapay zeka modelleri geliştirilmişti fakat bu modeller satranç ve Go gibi oyunlardan farklı bir model yapısındaydılar.
Geçtiğimiz günlerde Google’ın DeepMind’ı hem satranç hem de bu gibi atari tarzı oyunları oynayabilen bir yapay zeka modeli hakkında bir makale yayınladı. Satranç ve Go gibi oyunlarda çalışan algoritmalar, planlamalarını ağaç temelli bir yaklaşım kullanarak yaparlar ve bu sayede ilerde yapılacak olası hamleleri dallandırarak öngörürler. Bu yaklaşım hesaplama açısından pahalı bir yaklaşımdır.
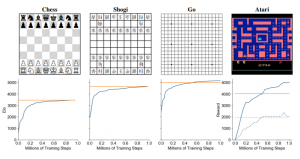
Bu algoritmalar sadece gördüklerini (bir atari oyunu için ekrandaki piksellerin konumu gibi) değerlendirir ve buna göre bir eylem seçer. Oyunun durumunun tamamen kesin bir modeli yoktur ve modelin eğitim süreci büyük ölçüde bu bilgi verildiğinde hangi yanıtın uygun olduğunu bulmaya dayanır.
DeepMind’ın MuZero adını verdiği yeni sistem, kısmen DeepMind’ın kendine satranç ve Go gibi kural tabanlı oyunlarda ustalaşmayı öğreten AlphaZero AI ile çalışmasına dayanıyor. Ancak MuZero, onu önemli ölçüde daha esnek kılan yeni bir yaklaşım da ekliyor. Bu yaklaşıma “model tabanlı pekiştirmeli öğrenme” denir. Bu yaklaşımı kullanan bir sistemde yazılım, oyun durumunun dahili bir modelini oluşturmak için oyunda gördüklerini kullanır. İşlerin pekiştirme öğrenme kısmı, yapay zekanın kullandığı modelin hem doğru olduğunu hem de karar vermek için ihtiyaç duyduğu bilgileri içerdiğini nasıl anlayacağını öğrenmesine olanak tanıyan eğitim sürecini ifade eder.
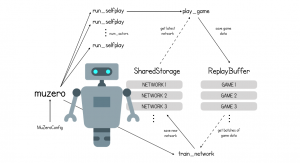
Genel olarak bu model yapay zekanın günümüzde ne kadar ilerlediğinin bir kanıtı sayılabilir. Geçtiğimiz dönemlerde tek bir görevi yapması için eğitilen yapay zekalar bugün birden fazla göreve yanıt verebilecek seviyeye gelmişlerdir. Bu modellere milyonlarca satranç oyununu oynamayı mümkün kılan ise daha yüksek işlem gücünün varlığıdır.